
Harmonia Macrocosmica
Marée démographique, appauvrissement linguistique
Le 15 novembre 2022, nous avons appris que notre planète comptait désormais huit milliards d’êtres humains. Paradoxalement, la perte de la diversité linguistique mondiale est inversement proportionnelle à l’accroissement rapide de la population terrestre. Actuellement, près de 7100 langues sont encore pratiquées de par le monde. Pour sa part, l’Europe n’abrite que 4% du total, alors qu’une petite vingtaine – dont le mandarin, l’hindi, l’anglais, l’espagnol, l’arabe, le français, le russe et le bengali – sont utilisées quotidiennement par 95% de la population mondiale, soit comme langue principale, soit comme “seconde” langue. Sur l’ensemble des langues recensées, la moitié d’entre elles comptent moins de 10 000 locuteurs et un quart moins de 1 000. En moyenne, 25 langues et dialectes disparaissent définitivement chaque année, tendance qui nous fait craindre qu’à la fin de ce siècle la moitié des langues parlées aujourd’hui pourraient être mortes.
De nombreuses initiatives sont engagées dans le monde pour tenter d’enrayer le déclin linguistique, voire inverser la tendance, mais beaucoup de langues, pratiquées par un nombre très restreint de locuteurs souvent très âgés, semblent d’ores et déjà condamnées. Or, comme l’a résumé Claude HAGÈGE : “Une langue qui disparaît, ce ne sont pas seulement des textes qui se perdent. C’est un pan entier de nos cultures qui tombe. Avec la langue meurt une manière de comprendre la nature, de percevoir le monde, de le mettre en mots. Avec elle disparaît une poésie, une façon de raisonner, un mode de créativité. C’est donc d’un appauvrissement de l’intelligence humaine qu’il est question.” À l’heure où la globalisation mondiale semble s’accélérer, le sujet est loin d’être anecdotique ou “passéiste” et nous concerne tous, de près ou de loin.
Pour sauvegarder une partie de la diversité linguistique de notre monde une parade a été imaginée, consistant à enregistrer et archiver les idiomes les plus menacés pour éviter qu’ils ne sombrent totalement dans l’oubli à la mort de leur dernier locuteur. En France, c’est un service du Centre national de la recherche scientifique (CNRS) qui se consacre à cette tâche d’envergure titanesque, à travers le laboratoire de Langues et Civilisations à Tradition Orale, plus connu sous l’acronyme Lacito (logo ci-dessous).
![]()
LACITO, un organe d’excellence
Créée en 1976 par la linguiste Jacqueline THOMAS, cette unité de recherche mixte est dédiée à l’étude de la culture des peuples et des ethnies qui n’ont eu recours à l’écrit que récemment, parfois même jamais et qui, surtout, sont “sous-documentés”. Le laboratoire prête une attention particulière à l’étude des langues parlées par des groupes minoritaires, vivant le plus souvent dans des environnements ruraux, au sein de pays plurilingues ; situation d’isolement qui en accélère le déclin. Par la nature même de ses investigations, le travail du LACITO se veut pluridisciplinaire car placé au croisement de domaines aussi divers que la linguistique, l’ethnologie, la médecine, la mythologie, les arts et l’anthropologie, laquelle inclut la musique et les chants.
Cette mission d’étude et d’archivage repose essentiellement sur des enquêtes de terrain. Du fait d’un caractère d’urgence dû à l’érosion très rapide de certaines langues, les chercheurs, allant directement à la source, vont rencontrer les locuteurs sur place. De nos jours, le LACITO est présent sur les cinq continents, du nord de la Grèce au Caucase, des confins de la Chine au Mexique et à l’Alaska, du Vanuatu à l’Italie, en passant par le Cameroun, le Yémen, la Mauritanie, la Birmanie et le sud de l’Inde. Certaines zones sont particulièrement privilégiées, comme le très vaste territoire des langues tibéto-birmanes et austro-asiatiques menacées et peu étudiées. Ce travail de fond, intense et méthodique, a permis de doter des idiomes d’une solide documentation qualitative et quantitative, pour éviter que des cultures ne sombrent corps et biens dans un oubli définitif. Une fois la matière recueillie, elle est synthétisée, archivée et valorisée par le LACITO, dont le but premier consiste à créer des bases de données auxquelles pourront accéder les universitaires et les chercheurs.
À l’issue de plusieurs décennies de collecte et de travail, ce sont des milliers de documents et des lexiques qui ont été produits et inventoriés, donnant lieu à leur tour à des analyses linguistiques poussées. Il restait cependant à mettre au point un outil qui permettrait au public de profiter de cette inestimable ressource, plus particulièrement de la “matière première“, c’est-à-dire des précieux enregistrements audio et vidéo réalisés au cours des missions sur le terrain. C’est pourquoi, à partir de 1995, a été engagé un vaste chantier consistant à réaliser un fonds d’archives qui permettrait à qui le souhaite de bénéficier à volonté des possibilités nouvelles de l’informatique et d’Internet.
PANGLOSS, la bien nommée
C’est dans ces conditions que les fragiles bobines, cassettes et CD, qui nécessitaient des conditions draconiennes de conservation, vont faire l’objet d’un méticuleux travail de numérisation qui s’étalera sur des années. En 2001, la base de données ne compte qu’une centaine de documents – essentiellement des transcriptions – rédigés en une vingtaine de langues. Dix ans plus tard, on y retrouve un millier d’enregistrements en 67 langues. En 2012, ce fonds prend le nom évocateur de PANGLOSS, né de l’association de deux termes du grec ancien – Pan “toutes” et Gloss “langues” –, tout en faisant référence au personnage homonyme créé par VOLTAIRE pour son Candide. À peine mise en ligne, l’interface doit être repensée et réaménagée. En effet, en moins de cinq années, le nombre de fichiers audio et vidéo a plus que doublé, développement qui a conduit à repenser l’ergonomie de l’ensemble grâce à un moteur de recherche plus performant. Par ailleurs, il est également prévu à terme de pouvoir accéder directement sur le même site à la collection de lexiques et de dictionnaires réalisés par les chercheurs du LACITO.
Le nouveau site (ci-dessous) est opérationnel dès le début de 2021.
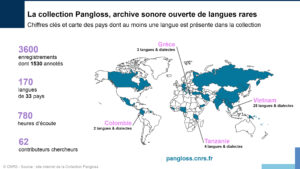
En 2021, ce sont 183 langues qui sont accessibles à travers plus de 3 600 enregistrements représentant 800 heures d’écoute et de transcriptions interlinéaires. Si cette base de données est essentiellement issue du LACITO proprement dit, elle reste ouverte à des dépôts extérieurs venus d’autres centres et unités de recherche ; l’objectif prioritaire restant la constitution d’une bibliothèque numérique destinée aux chercheurs de tous horizons. Ce laboratoire du CNRS travaille en étroite collaboration avec I’INALCO et l’Université Sorbonne Nouvelle-Paris 3.
Chaque internaute qui le souhaite peut désormais naviguer sur la carte interactive du site pour s’initier aux langues menacées. C’est ainsi qu’il est possible, par exemple, de découvrir le nashta, un dialecte slave qui survit en Grèce du Nord, le mbugwe de Tanzanie, le limbu du Népal, le chrau du Vietnam, le bjedough, dialecte tcherkesse du Caucase, le futunien, le romani du Mexique, le xârâcùù de Nouvelle-Calédonie ou encore le khroskyabs du Sichuan, le valoc’ de Lombardie ou le war, dont les locuteurs se répartissent entre l’État indien du Meghalaya et le nord du Bengladesh.
PANGLOSS a également intégré certaines langues dépourvues à nos jours de locuteurs “natifs”. C’est par exemple le cas de l’oubykh, une langue circassienne agglutinante qui utilise 83 consonnes, et dont le dernier représentant est décédé en 1992. Mais cette langue morte avait eu la chance d’avoir été étudiée et compilée par l’anthropologue, historien et linguiste George DUMÉZIL, lequel l’a définitivement sauvée de l’oubli grâce à une abondante documentation écrite et des enregistrements audio.
En référençant et en mettant directement à disposition du monde des chercheurs des données primaires, la démarche de la collection PANGLOSS s’inscrit dans une philosophie de “science ouverte”. Elle évite ainsi que les données scientifiques ne restent inexploitées ou “ensevelies” dans des fonds d’archives. PANGLOSS appartient en outre au réseau international Digital Endangered Languages and Musics Archives Network (DELAMAN). La collection est également hébergée par la plateforme Cocoon (acronyme de Collection de corpus oraux numériques), qui fait partie du réseau international Open Language Archive Community (OLAC). Le pari, visant à faire sortir “hors les murs” la richesse du fonds du LACITO, se trouve donc largement gagné. Reste à se préoccuper de l’avenir car, dans le domaine linguistique comme dans d’autres, l’heure est désormais à l’urgence et au temps compté.
Pour Alexis MICHAUD, il faut organiser le travail des chercheurs de terrain pour que le résultat de leurs investigations et enquêtes puisse être partagé le plus rapidement possible : “Il faut que les chercheurs prennent l’habitude de mettre leurs archives sonores en ligne au fur et à mesure de leurs travaux, plutôt que d’attendre la fin de leur carrière pour s’y atteler. Tant pis si toutes n’ont pas encore de transcription écrite.” Pour y remédier, il est prévu qu’un logiciel de traitement automatisé du langage soit installé pour faciliter la tâche des chercheurs car, “jusqu’ici, il fallait une centaine d’heures d’enregistrement au moins pour entraîner une intelligence artificielle à faire des transcriptions dans une nouvelle langue. Avec l’interface que nous préparons pour le site sur la base des derniers outils disponibles, une heure d’enregistrement suffira, c’est une vraie révolution”.
Si vous souhaitez creuser le sujet que nous venons d’évoquer, nous vous proposons de visionner cette vidéo extraite du site Canal-U.
en relation





