
La Bibliothèque universelle de Fernando COLOMB
L’ambitieux projet de Paul IMBS
À l’écart de la compétition qui, chaque année, oppose Larousse, Robert et Hachette, un autre dictionnaire de langue française connaît une audience remarquable tout en restant très peu médiatisé et largement méconnu d’une grande partie du public : Le Trésor de la langue française, plus connu sous l’acronyme TLF. De nos jours, le site web qui héberge ce lexique, un des plus complets de notre langue et, qui plus est, accessible gratuitement en ligne, revendique en moyenne 750 000 requêtes quotidiennes. Il ne propose pas moins de 100 000 mots avec leur étymologie et leur histoire, 270 000 définitions et 430 000 citations. Cette œuvre exceptionnelle est le fruit d’un travail considérable dans lequel, dès le départ, l’outil informatique a joué un rôle central. Résolument innovante, la conception du TLF a bouleversé à jamais les règles et les méthodes de travail “artisanales” qui, jusqu’alors, prévalaient dans la lexicographie française.
Au début des années cinquante, le Dictionnaire de la langue française d’Émile LITTRÉ tombe dans le domaine public. Cet ouvrage s’impose alors comme la référence pour tout ce qui relève de l’analyse étymologique et historique grammaticale du vocabulaire français. Le moment est donc venu de reprendre le corpus de LITTRÉ pour le corriger, le compléter et surtout le prolonger, en tenant compte de l’évolution de la langue jusqu’au XXe siècle. C’est un professeur de philologie romane de l’université de Strasbourg qui va s’investir dans ce projet et lui permettre d’aboutir, après des années d’efforts ininterrompus : Paul IMBS (ci-dessous).

Né à Sélestat en 1908, le jeune Alsacien qui a suivi sa scolarité à l’école allemande, où il s’est pris de passion pour le latin, doit attendre 1918 pour découvrir le français. Spécialisé dans la littérature française médiévale, il obtient l’agrégation de grammaire en 1932 avant d’enseigner dans plusieurs lycées d’Alsace et de la région parisienne. Puis, en 1946, il intègre l’université de Strasbourg, successivement comme attaché aux recherches, maître de conférences, puis professeur.
En novembre 1957, il assiste dans la capitale alsacienne à un colloque international consacré à la lexicologie et à la lexicographie. Cet événement donne l’occasion à IMBS d’exposer son projet de Trésor de la langue française, nom qui fait directement référence au Thresor de la langue françoise tant ancienne que moderne, publié en 1606 par Jean NICOT. Il déclare “poursuivre un double but : être le témoin objectif et impartial du vocabulaire français, mieux connu parce que mieux inventorié ; être ce qu’avait été le Littré pour son temps : un exemple type de lexicographie scientifique moderne “. Dépourvue de soutien financier, l’entreprise connaît des débuts laborieux, mais l’apprenti lexicographe garde le cap et parvient à bénéficier de soutiens politiques de poids. Déplorant que l’institution universitaire ne se soit pas suffisamment impliquée dans les grandes réalisations lexicographiques de la langue française, il entend remédier à cet état de fait grâce à l’utilisation des nouveaux moyens automatisés que représentent les ordinateurs.
En décembre 1960, le Centre de recherche pour un Trésor de la langue française (CRTLF), organisme patronné par le CNRS, est officiellement créé à Nancy, ville dont IMBS est devenu le recteur de l’université. Dès lors le travail de collecte, de documentation et de rédaction peut démarrer pour de bon. Mais l’élément qui va changer la donne est l’arrivée, en 1963, d’un très puissant ordinateur, le Gamma 60 de Bull. Cet outil performant mais très volumineux – au point qu’il faudra construire une annexe pour l’héberger – permet à plus d’une centaine de chercheurs et de techniciens de constituer une base de données, qui comprendra au final près de 180 millions de mots. Ce résultat sera le fruit d’un travail de dépouillement d’un nombre considérable de sources, dont en particulier tous les dictionnaires français publiés depuis l’an 1500.
Un travail de bénédictin
En 2009, Jean-Marie PIERREL résumera ainsi le déroulement de cette importante phase de collecte : “Le Trésor de la langue française est le premier dictionnaire de langue se fondant sur une méthodologie systématique d’analyse des usages effectifs des mots de notre langue à travers l’exploitation d’une vaste base de données textuelles, dont la saisie a débuté dès les années soixante, et dont le but premier était de fournir des données organisées aux rédacteurs du dictionnaire. Ainsi, un rédacteur ayant à écrire un article se trouvait doté de concordances systématiques de ce mot, triées suivant différents critères : ordre chronologique des sources, ordre alphabétique des contextes gauche et droit, ou encore ordre défini selon les constructions syntaxiques propres à chaque partie du discours. Ces concordances étaient utilisées pour un premier tri de la documentation et permettaient d’obtenir, dans un second temps, des contextes élargis, parmi lesquels furent sélectionnés les exemples finalement retenus dans le dictionnaire.” Une fois cette base réalisée, commence alors un exigeant travail de synthèse et d’écriture qui aboutira en 1971 à la parution du premier volume (ci-dessous). Remarquons au passage que la jaquette de ce volume porte l’image des bandes perforées qui ont permis de saisir les textes dans l’ordinateur.

Infatigable, IMBS supervise personnellement les sept premiers volumes, qui s’échelonnent jusqu’en 1979. En 1977, après le départ à la retraite de celui qui, pour la postérité, restera l’initiateur du projet, le flambeau est repris par un autre homme à forte personnalité, figure importante de la lexicologie : Bernard QUEMADA (ci-dessous). Ce dernier, qui collabore depuis longtemps au projet, peut être considéré comme le véritable pionnier de l’utilisation de l’outil informatique appliqué au domaine de la lexicographie. Au Centre d’étude du vocabulaire français de Besançon, dès septembre 1958, il avait installé des Laboratoires d’Analyse Lexicologique (LAL). Initiateur d’une méthodologie “mécanographique” – le terme ʺd’informatisation” n’est alors guère utilisé – pour dépouiller plusieurs centaines de textes littéraires français, il entreprend de dresser un inventaire dans le but de réaliser un catalogue exhaustif du vocabulaire utilisé. La convergence entre les deux projets, le sien et celui de IMBS, s’imposant d’évidence, il fait bénéficier le TLF de son expertise en le dotant d’un programme de documentation informatisée.

Une fois installé aux manettes, QUEMADA réorganise l’ensemble en créant l’Institut NAtional de la Langue Française (INALF). Non content de poursuivre, avec une grande efficacité, la parution des volumes papier, il s’attache à développer les travaux réalisés en amont, et donc la base de données. Cette dernière devient en quelques années un modèle du genre, riche de plusieurs milliers de textes dépouillés et saisis. Indépendamment de son utilisation pour le TLF, la base de données va s’autonomiser pour prendre le nom de Frantext. Accessible en ligne depuis 1998 et doté d’outils de recherche performants, en 2019 ce service totalise 5430 références, datées de 1180 à 2013, dont 1300 textes postérieurs à 1950.
En 1994, avec la publication du seizième et dernier volume du TLF, le projet est parvenu à son terme, mais la mission des lexicographes qui ont accompli ce tour de force n’est pas pour autant terminée. Un volume de suppléments, qui ne sera pas édité, est rédigé entre 1992 et 1997 afin de prendre en compte l’évolution de la langue par l’intégration de 10 000 mots nouveaux. Mais, alors que l’utilité et la qualité du TLF sont quasi unanimement saluées, c’est désormais son format qui suscite la critique car, à l’instar des autres grands dictionnaires, le Trésor souffre d’être à la fois lourd, encombrant et coûteux. Par ailleurs, les grandes publications lexicographiques sont confrontées à l’irruption rapide des “nouvelles technologies” avec, en particulier, l’apparition du cédérom ; lequel, dès les années quatre-vingt-dix, se verra lui-même supplanté par l’internet grand public.
Le Trésor en version numérique
C’est ainsi, qu’avant même l’achèvement de la publication des volumes “papier”, une réflexion est engagée sur l’opportunité d’une version numérique. Certes, dès le départ de l’aventure TLF, l’outil informatique était intimement lié à la conception des volumes, mais son rôle se cantonnait au traitement des informations et à leur intégration dans la base de données. Changement de cap, la priorité porte désormais sur la numérisation du contenu et l’utilisation du web pour rendre l’ouvrage facilement accessible au plus grand nombre. C’est ainsi que, sous l’impulsion de Bernard CERQUIGLINI et de Robert MARTIN, des prototypes de volumes informatisés seront conçus et mis en ligne.
Afin de mener à bien ce projet et donner une nouvelle dimension à un TLF renouvelé, une unité mixte de recherche est créée en janvier 2001 à l’université de Nancy. Elle porte le nom Analyse et Traitement Informatique de la Langue Française, ou ATILF. Avec le soutien très actif du CNRS, le projet avance vite, de sorte qu’au printemps 2002, le directeur de l’ATILF, Jean-Pierre PIERRIEL, peut fièrement présenter l’ensemble des volumes papier numérisés mis en ligne : le Trésor de la langue française informatisé, plus connu sous l’acronyme TLFI, est officiellement né (ci-dessous). Précisons que cette base de données est “relayée” par le Centre national de ressources textuelles et lexicales (CNRTL), organisme qui regroupe plusieurs ressources linguistiques du français en ligne.

Afin de compléter l’offre, une version C.D.-Rom est mise en vente en novembre 2004. Signalons qu’à la même époque, le Nouveau Littré, également mis en ligne, devient accessible gratuitement aux établissements scolaires et universitaires. Structuré en XML et doté de millions de balises, le TLFI identifie chaque objet textuel contenu dans un article : définition, exemple, auteur d’exemple, etc. Il est en outre couplé avec un logiciel d’interrogation surpuissant, Stella, qui permet les recherches les plus fines et les investigations multicritères. Comme le déclare Pascale BERNARD, “en un clic, des milliers de pages se croisent et interagissent”. Un article publié dans Le Point, en septembre 2014, présente des exemples concrets de ce qu’il est possible de faire avec le Trésor version informatisée : ” Tous les noms composés comprenant le mot pied, les onomatopées (de coin-coin à zzz !) ou le vocabulaire de l’ostréiculture. Combiné avec un code grammatical et un indicateur d’emploi, le moteur affine la requête et extrait, par exemple, tous les mots issus du norvégien ou les verbes tirés de l’argot illustrés par un vers de Victor HUGO. Chacun peut se constituer son petit dictionnaire et lister les mammifères rongeurs (24 entrées) ou les outils se terminant en oir. La recherche complexe permettra d’obtenir les conjugaisons du verbe vaincre, les substantifs du domaine de la marine en rapport avec la manœuvre des voiles, ou la liste des apocopes masculines (intello, mono, alcoolo, etc.). Les cruciverbistes à la peine trouveront en un clic les mots dont les deux premières et les quatre dernières lettres sont inconnues et comprennent entre les deux un “a” et un “m” (alambic, araméen, chamade, etc.).”
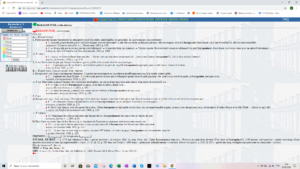 Si certains regrettent la présentation austère du site et quelques menues erreurs souvent dues au fait que le TLF a été numérisé sans corrections préalables, il faut admettre que le site, très impressionnant, procure bien du plaisir à tous les amoureux des mots. Regrettons cependant que cet outil précieux reste toujours assez méconnu en France même, alors qu’il est beaucoup utilisé dans le reste du monde.
Si certains regrettent la présentation austère du site et quelques menues erreurs souvent dues au fait que le TLF a été numérisé sans corrections préalables, il faut admettre que le site, très impressionnant, procure bien du plaisir à tous les amoureux des mots. Regrettons cependant que cet outil précieux reste toujours assez méconnu en France même, alors qu’il est beaucoup utilisé dans le reste du monde.
Pour aller plus loin, nous vous proposons de consulter Le Trésor de la Langue Française Informatisé : dictionnaire de référence accessible à tous, de Jean-Marie PIERRIEL, ou Le Trésor de la langue française informatisé de Pascale BERNARD. Ci-dessous une petite vidéo, muette, qui donne un bref aperçu du fonctionnement du TLFI.
en relation





